AI Agents for Document Processing
Your team processes hundreds of documents a day. Invoices, contracts, applications, compliance forms. Most of that work is reading, copying fields into a system, and routing to the next person. AI agents do all of it faster and with fewer errors.
The Problem
A typical operations team processes 1,200 mixed documents a day: vendor invoices, customer contracts, onboarding forms, shipping manifests, KYC documents. A single invoice takes a clerk 5 to 10 minutes to key into NetSuite or SAP. A contract sits in a review queue for 3 to 7 days waiting for someone to extract term dates, payment schedules, and renewal clauses. Data entry errors show up downstream: a transposed PO number causes a $40,000 payment to the wrong vendor, a missed contract renewal triggers auto-renewal on terms nobody wanted, a KYC form with a misread date pushes a customer into the wrong compliance cohort. Every new vendor template means another junior hire needs a week to learn the format. Legacy OCR tools handle 60% of clean scans and fail on the rest. The real bottleneck isn't the tooling. It's that every new format and every low-confidence field routes to a human, and the human queue is always growing faster than the team.
How AI Agents Solve It
A Claude Sonnet 4.5 agent with a layout-aware vision model reads each document regardless of format. It classifies the document type (invoice, contract, W-9, BOL, claim form, passport), extracts the fields you care about into structured JSON, validates against your business rules, and writes the result into the right downstream system through API. For contracts, it pulls key terms (parties, effective date, term length, payment terms, termination clauses, governing law) into a CLM system like Ironclad or DocuSign CLM. For invoices it writes to NetSuite or SAP with the PO matched. For KYC forms it posts to the identity workflow. Low-confidence extractions (below 95% per field) route to a human review queue with a side-by-side view of the source document and the extracted fields. Every decision logs the model version, the extraction confidence, and the reviewing user if applicable.
How It Works
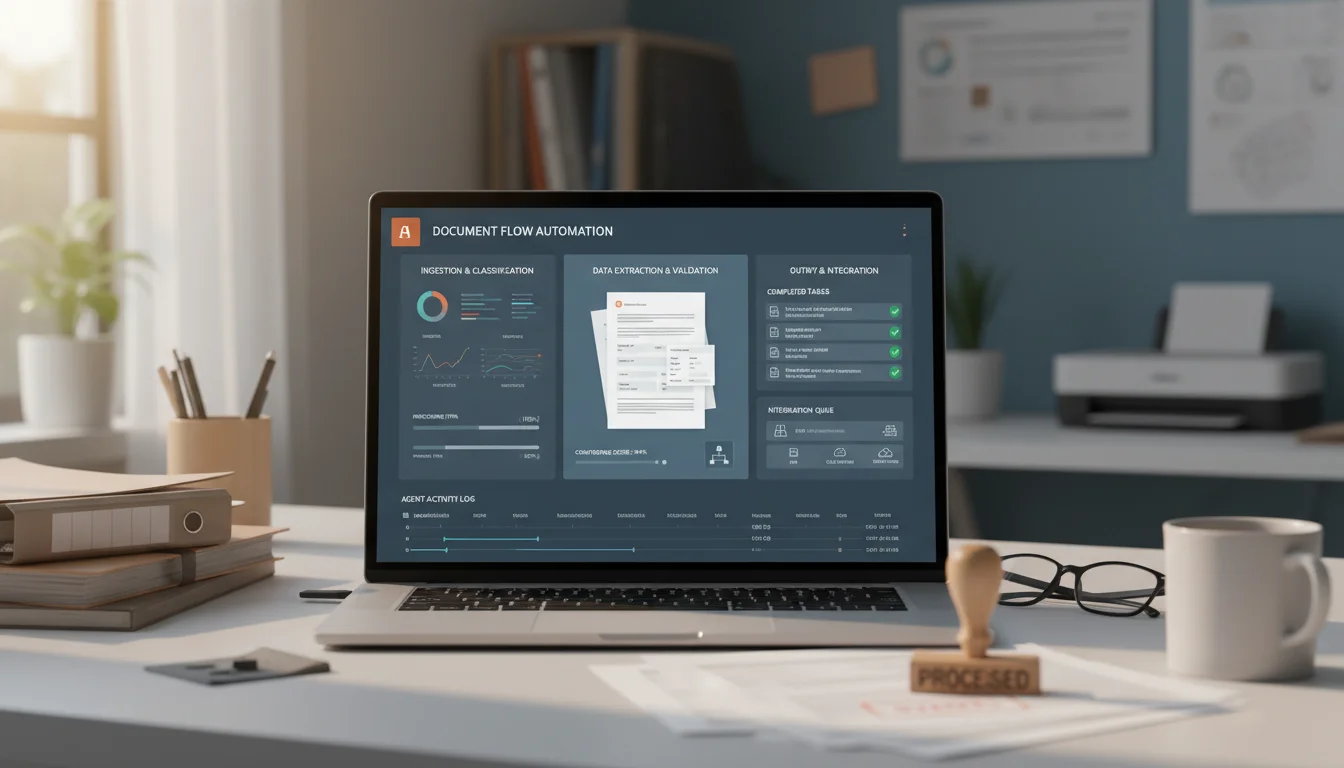
Ingest and Classify
Documents arrive through a monitored email inbox, an SFTP drop, a web upload form, or a REST API endpoint. The agent identifies the document type (invoice, contract, form W-9, shipping manifest, insurance claim, ID document) using a classifier trained on your historical mix plus general document types. For each recognized type, it selects the matching extraction template or schema. Multi-document PDFs get split into constituent documents first. Failure modes: if the classifier confidence is below 85%, the document routes to a human classification queue rather than being processed with the wrong template, which would cause silent errors downstream.
Extract and Validate
The agent pulls structured fields using a layout-aware vision model (tables preserved, forms understood as key-value pairs, signatures located). For an invoice, it extracts vendor name, invoice number, date, line items, tax, total, PO reference. For a contract, parties, effective date, term, payment schedule, renewal clauses, governing law. Each extracted field has a bounding box and a confidence score. Business rules validate: totals sum correctly, dates are plausible, PO numbers exist in the ERP, tax rates match jurisdiction. Failure modes: if a required field cannot be located, the document routes to review rather than writing a null value that breaks downstream processing.
Route and Store
Validated extractions flow into the right system of record through API. Invoices post to NetSuite, SAP, Oracle, or Bill.com with the PO matched and tax code applied. Contracts post to Ironclad, DocuSign CLM, or SharePoint with term-based calendar events scheduled. KYC forms post to the identity workflow with confidence scores visible to the compliance team. Each document is tagged, indexed in OpenSearch, and made searchable by content. Exceptions (low confidence, missing fields, validation failures) route to a human review queue with a purpose-built UI showing source and extracted fields side by side. Failure modes: downstream API failures trigger retry with backoff, and persistent failures hold the document in a pending state rather than dropping it.
What You Get
Process documents in seconds
A typical invoice that takes a clerk 5 to 10 minutes to key takes the agent under 10 seconds, including validation and posting. For 1,200 documents a day, that reclaims roughly 100 clerk-hours daily. Clean documents flow through without human touch. Only exceptions reach your team, and the exception queue typically represents 8 to 12% of volume instead of 100%.
Fewer data entry errors
The agent reads numbers and dates consistently and validates them against business rules before writing. Extraction accuracy on common formats sits at 97 to 99% and improves as your team confirms edge cases. Downstream error rates drop: one logistics client saw misdirected payments fall 91% and contract renewal surprises fall to zero in the first year because auto-renewal triggers were always captured at intake.
Handle any format
The agent reads PDFs, scanned TIFFs, photos taken from a phone, Word documents, emails with attachments, and faxed documents that arrived as images. No custom template required per vendor. When a new vendor starts sending invoices in an unfamiliar format, the agent extracts the standard fields on the first try most of the time. Traditional OCR would need a new template for each vendor layout.
Full audit trail
Every extraction decision is logged with the source document, the bounding box for each field, the confidence score, the model version, the validation rules applied, and the reviewing user if applicable. You can trace any data point in your ERP or CLM back to the original pixel in the source PDF. Auditors, controllers, and compliance teams get transparent evidence instead of trusting a black box.
Implementation
Timeline
3-phase, 4-6 weeks total: Week 1 discovery and integration plan, Weeks 2-4 build and evals, Weeks 5-6 shadow mode and cutover.
Human in the Loop
Reviewers look at any document with a field-level confidence below 95%, any new document type in its first two weeks, and any extraction that fails business rule validation. Contract extractions involving term length or payment terms above $100K always route to a human regardless of confidence. KYC documents always have a second reviewer before final posting. Auto-post thresholds are configurable per document type and per field, and they're reviewed quarterly against accuracy metrics. Override rates above 5% on a given document type trigger a retraining pass.
Stack
Integrations
Frequently Asked Questions
Can the agent handle handwritten documents?+
What document formats does it support?+
How does it learn new document types?+
Does it integrate with our existing systems?+
What happens when the agent isn't sure? Does it just guess?+
Who owns the decision if the agent gets it wrong?+
How is this different from RPA or traditional OCR we already use?+
Can we audit every decision the agent made?+
Ready to put AI agents to work?
We build production-grade AI agents for your specific workflows. Most projects go live in 4-6 weeks.